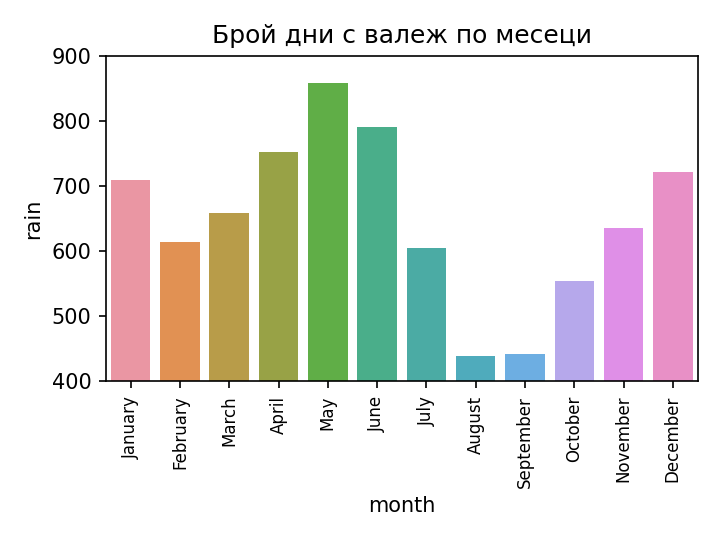
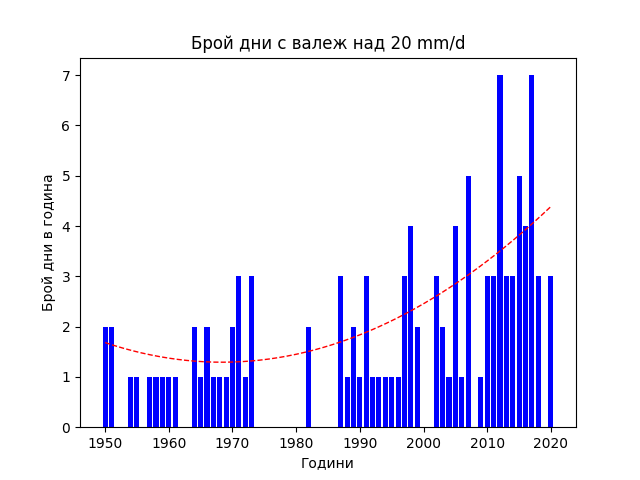
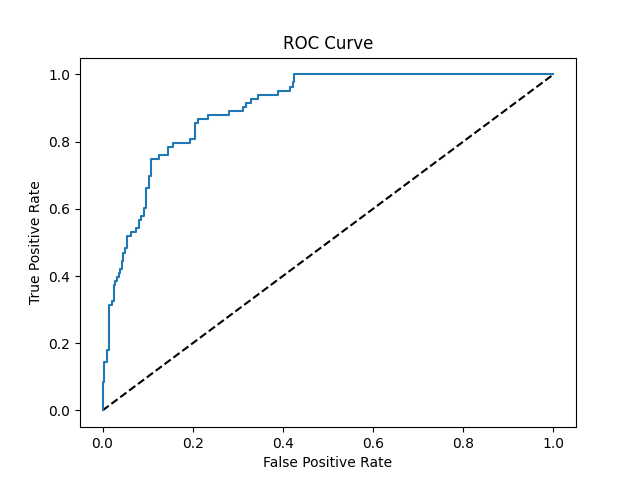
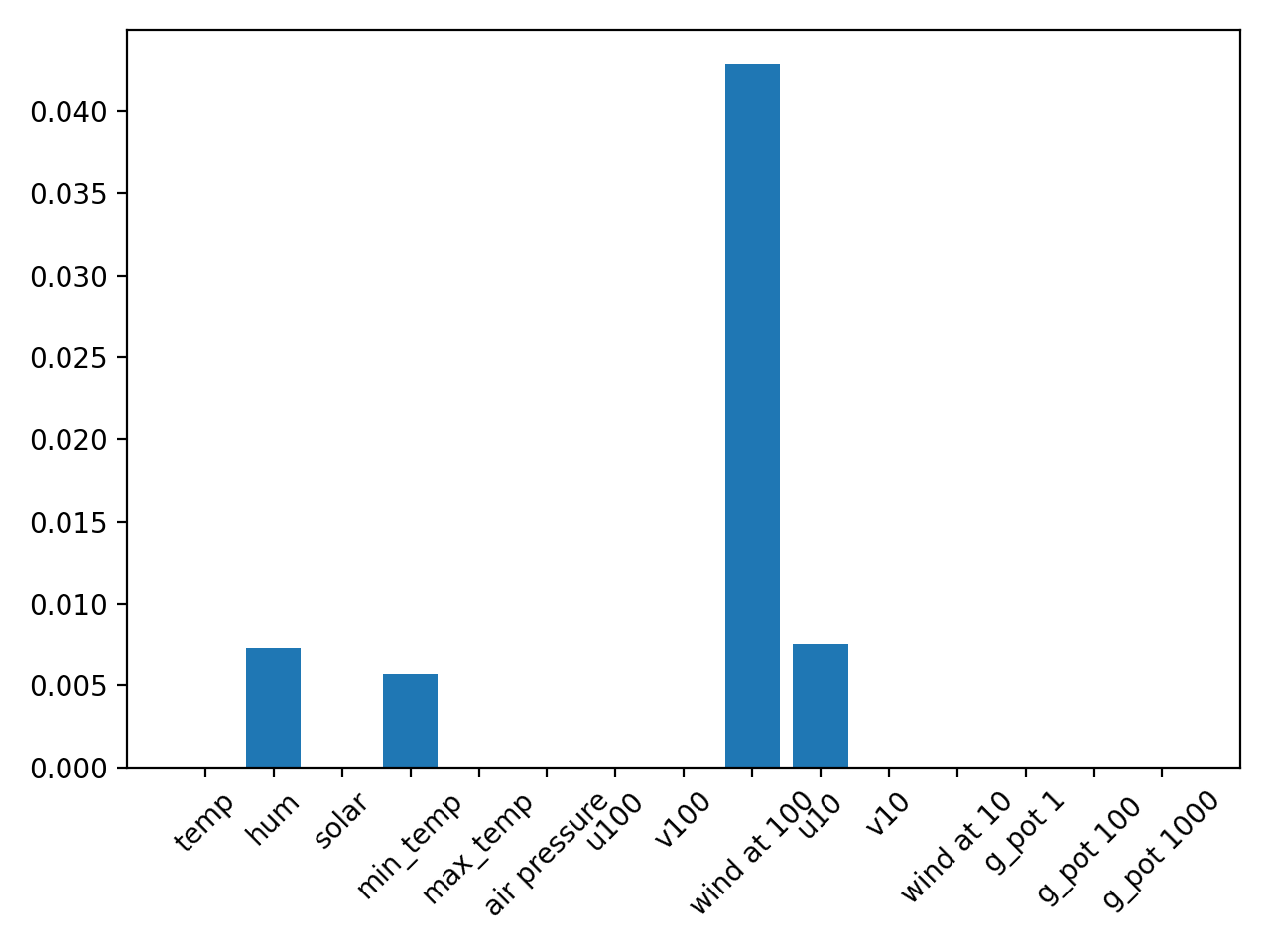
Kamchia River
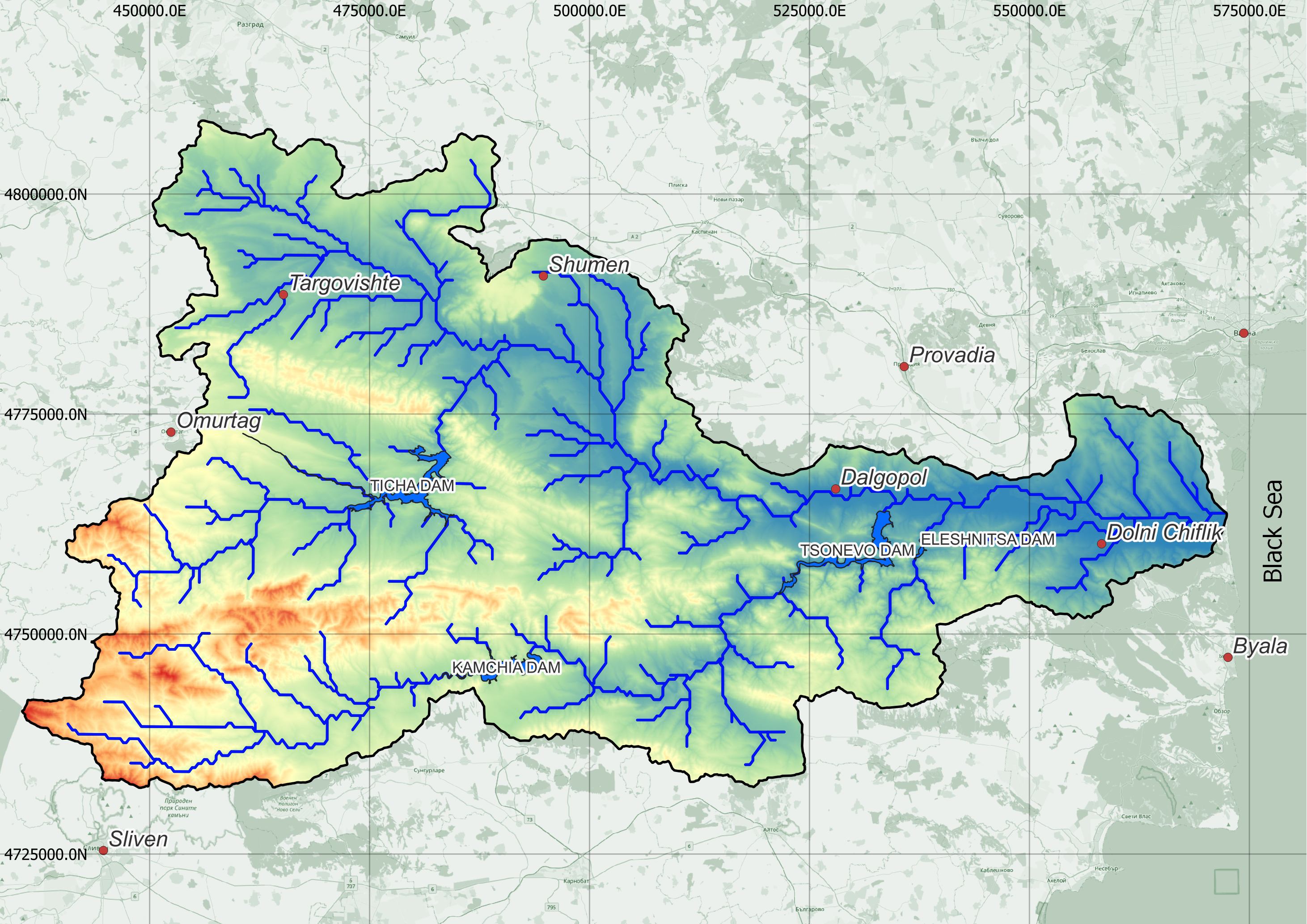
Kamchia is the longest Bulgarian river flowing into the Black Sea, draining almost the entire Eastern Stara Planina and a small part of the Danube Plain. The total length of the river is 244.5 km. Kamchiya River is formed by the confluence of Golyama Kamchiya (left tributary) and Luda Kamchiya (right tributary) rivers at 26 m above sea level, to the southwest corner of the village of Velichkovo, Dulgopol municipality. It flows in an eastern direction in a wide valley between the Avrensko (Momino) plateau in the north and the Kamchiiska mountain in the south. Along its valley runs the border between the Danube Plain and the Pre-Balkans. The estuarine parts of the valley are swampy and overgrown with riparian forests. It flows into the Black Sea at the Kamchia resort complex.
The are of the river basin is 5357,6 km2, as in the northwest and north it borders the river basins of the rivers Rusenski Lom and Provadiyska Reka, in the west - with the basin of the Yantra River, and in the south - with the basins of the rivers Tundzha, Aitoska, Hadjiyska, Dvoinitsa and Fundakliyska, as all except Tundzha flow into the Black Sea. The Kamchia river basin covers parts of 6 administrative regions in Bulgaria - the southern parts of Varna and Shumen regions, the northernmost parts of Burgas region, the eastern part of Targovishte region, the northeastern part of Sliven region and the southernmost parts of Razgrad region.