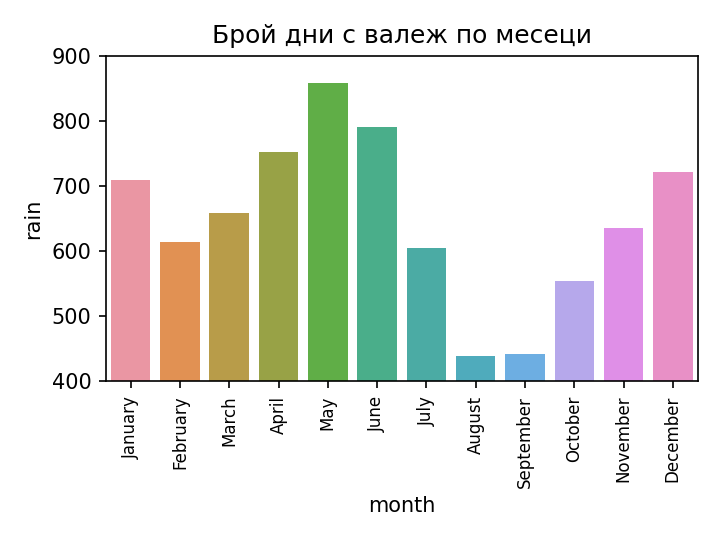
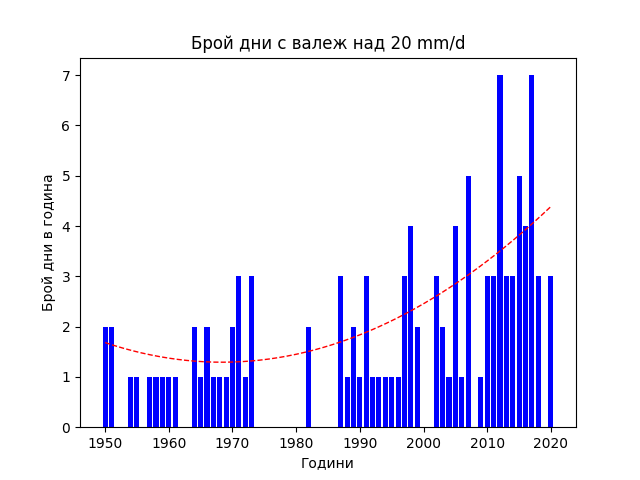
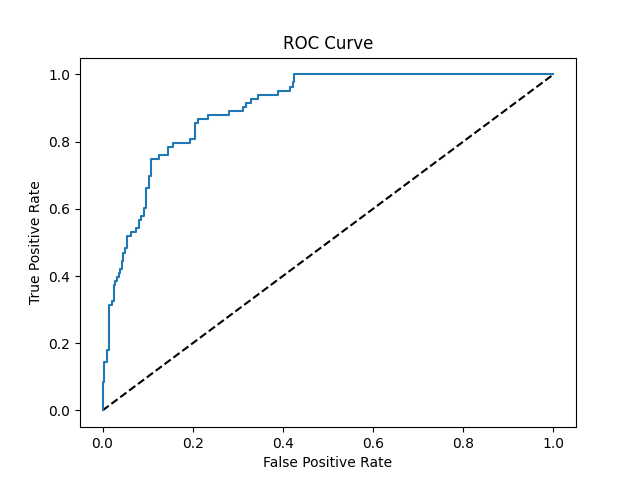
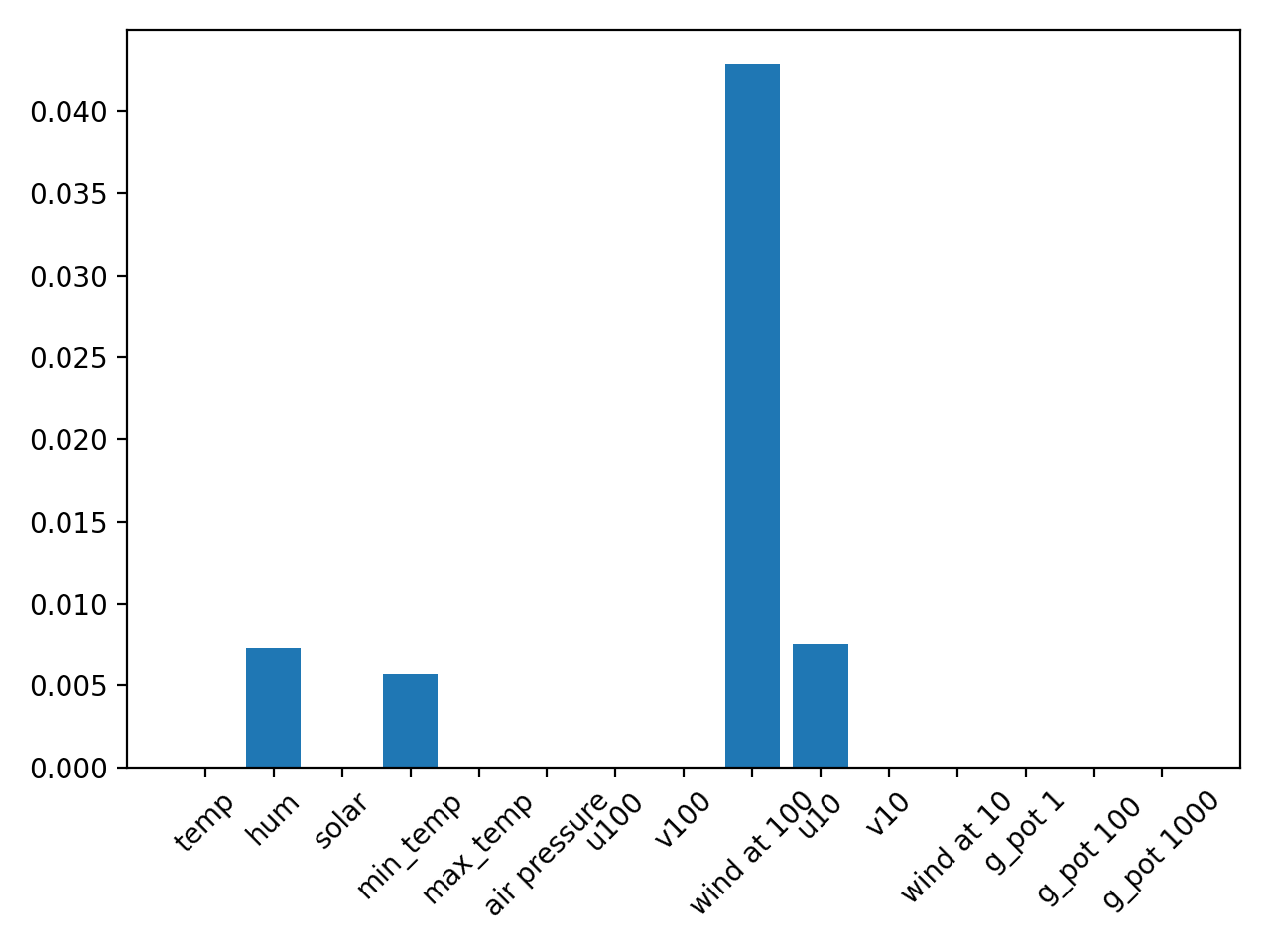
Камчия
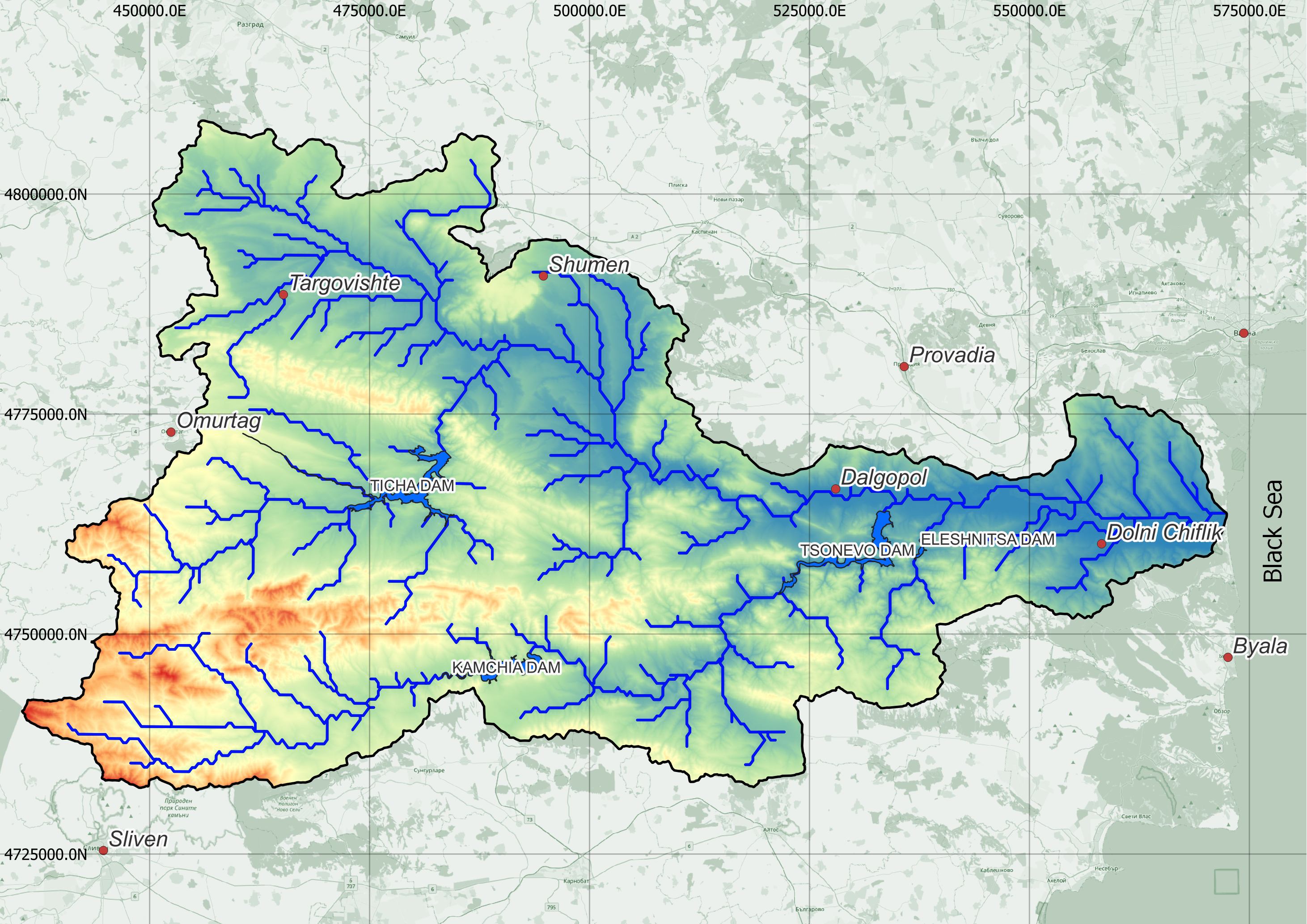
Камчия е най-голямата българска река, вливаща се в Черно море, като отводнява почти цяла Източна Стара планина и малка част от Дунавската равнина. Общата дължина на реката е 244.5 km. Река Камчия се образува от сливането на реките Голяма Камчия (лява съставяща) и Луда Камчия (дясна съставяща) на 26 m н.в., до югозападния ъгъл на село Величково, община Дългопол. Протича в източна посока в широка долина между Авренското (Момино) плато на север и Камчийска планина на юг. По долината ѝ се прокарва границата между Дунавската равнина и Предбалкана. Приустиевите части на долината са блатисти и обрасли с лонгозни гори. Влива се в Черно море при курортния комплекс „Камчия“.
Площта на водосборния басейн на реката е 5357,6 km2, като на северозапад и север граничи с водосборните басейни на реките Русенски Лом и Провадийска река, на запад – с водосборния басейн на река Янтра, а на юг – с водосборните басейни на реките Тунджа, Айтоска, Хаджийска, Двойница и Фъндъклийска, като всички без Тунджа се вливат в Черно море. Водосборният басейн на Камчия обхваща части от 6 административни области в България – южните части на Варненска и Шуменска области, най-северните части на Бургаска област, източната част на Търговишка област, североизточната част на Сливенска област и най-южните части на Разградска област.